Real World Data for Novel Health-Insurance products pilot: Diving into the system
Personalization of health insurance products needs to be based on continuous risk assessment of the individual, since lifestyle and behaviour cannot be assessed at one instance in time; they involve people’s habits and their continuous change. Health insurance products employing continuous assessment of customers’ lifestyle and behaviour are dynamically personalized.
The pilot focuses on health insurance and risk analysis by developing two AI-powered services risk assessment and fraud detection: The risk assessment service allows the insurance company to adapt prices by classifying individuals according to their lifestyle. The fraud detection service is based on outlier analysis for data, but mainly on the use of a virtual coach to advise individuals in their lifestyle choices, aiming at improving their health but also in persuading them to use the system correctly. These two services rely on a model of health outlook trained on the collected data and used in the provision of the services.
The pilot involves two systems:
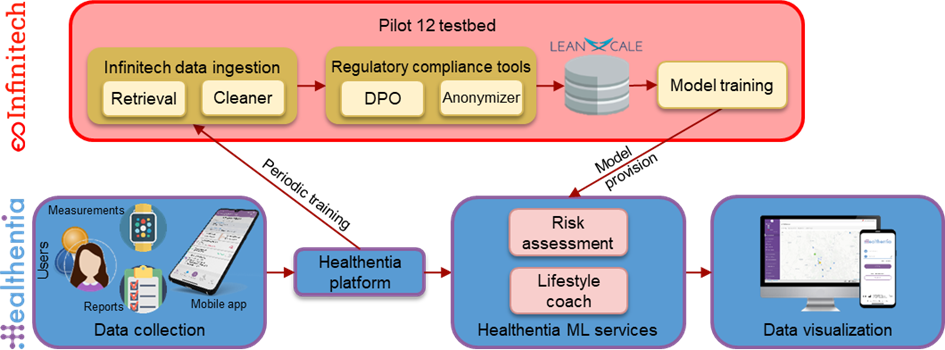
- The pilot #12 testbed, built within the INFINITECH project and deployed on the NOVA sandbox.
- The Healthentia e-Clinical platform, provided by Innovation Sprint.
Model training on the other hand takes place at the pilot #12 testbed in a secure and privacy-preserving way. This offline part is facilitated by the following INFINITECH components, deployed on the testbed:
- The Data Collection Tool continuously queries the Healthentia platform for new data, and its storage in the miniIO internal storage.
- The Regulatory Compliance Tools offer the Data Protection Orchestrator that is invoked to start a new model training process. It contacts the Data Collection Tool to retrieve the list of files in miniIO that should be included in the training process and then forwards this information to the Anonymization Tool.
- The Anonymization Tool loads the designated data from the miniIO storage and performs different levels of anonymization. It then stores the results in LeanXcale.
- The LeanXcale database hosts the data repository for model training. Data anonymized at different levels is stored here.
- The Model Trainer is a collection of Python classes handling (a) training, validation and testing dataset creation for different input attributes’ and output outcomes’ scenarios, (b) model training, (c) model evaluation and (d) model exporting to Healthentia.
The pilot is now starting a study with external participants. Stay tuned for the first use of its testbed for model training early 2022!